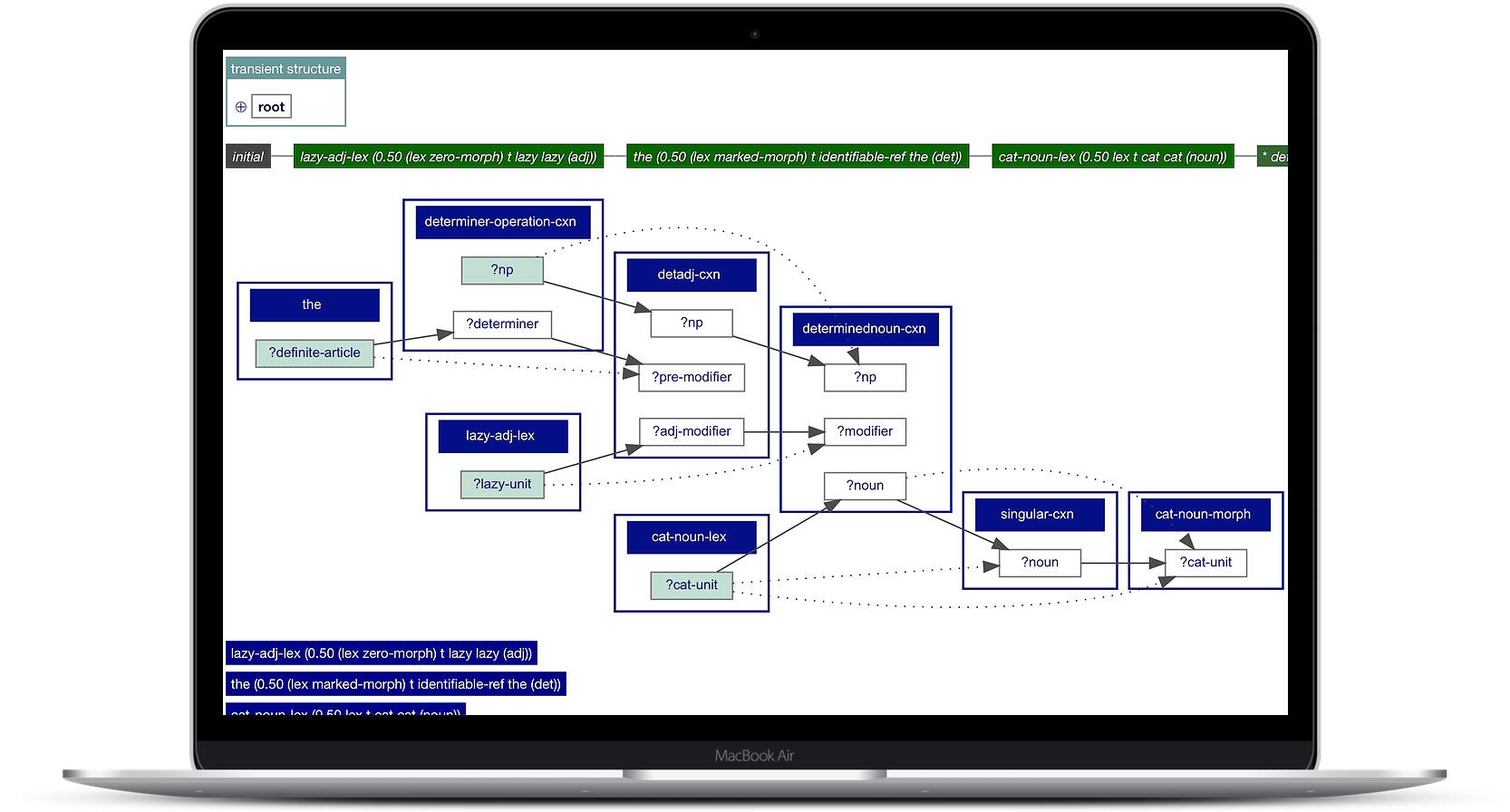
Babel is a flexible toolkit for implementing and running agent-based experiments on emergent communication. The Babel system includes advanced modules for constructional language processing and learning (Fluid Construction Grammar), conceptualising and interpreting procedural semantic structures (Incremental Recruitment Language), and conducting multi-agent experiments in simulated environments or using physical robots.
An extensive monitoring system opens up every detail of Babel’s intermediate representations and underlying dynamics. A modular design ensures that the system can be used in a wide variety of scenarios. It is therefore possible to use each component individually, according to your needs.
Babel is written in Common Lisp and runs in most major Lisp implementations (CCL, SBCL and LispWorks) on all major platforms (Linux, Mac OS, Windows). It is jointly developed by Sony Computer Science Laboratories Paris, Vrije Universiteit Brussel, KU Leuven and UNamur under an Apache 2.0 license.
If you only wish to use Fluid Construction Grammar or Incremental Recruitment Language, we offer a more user-friendly alternative through the FCG Editor. The FCG Editor offers all functionality of Babel's Fluid Construction Grammar and Incremental Recruitment Language systems through a powerful integrated development environment that can be installed in a single click.
Babel
The all-in-one toolkit for multi-agent experiments on emergent communication View on GitLab Get in touchHow to cite
A Practical Guide to Studying Emergent Communication through Grounded Language Games
Jens Nevens, Paul Van Eecke and Katrien Beuls
AISB19, Falmouth, United Kingdom, 2019.
The Babel2 Manual
Martin Loeztsch, Pieter Wellens, Joachim De Beule, Joris Bleys and Remi van Trijp
AI-Memo 01-08, AI-Lab VUB, Brussels, Belgium, 2008