Syntax and Semantics of FCG
Authors: Paul Van Eecke and Katrien Beuls
New to FCG? This document explains the basic components of the FCG system and gets you up to speed with the latest implementation. Interactive visualisations that accompany this text can be found here. The ultimate strategy for achieving a deep understanding however, consists in downloading the FCG system and playing around with a small grammar fragment.
Transient structures
Transient structures are represented as feature structures. Feature structures are widely used in grammar formalisms such as Lexical Functional Grammar, Generalized Phrase Structure Grammar, Head-Drive Phrase Structure Grammar, Sign-Based Construction Grammar and Embodied Construction Grammar. In FCG, the feature structures are not typed, which facilitates a dynamical addition, modification or deletion of features and values in a grammar.
A transient structure consists of a collection of units. The units have a unit name and a unit body, which consists of a set of feature-value pairs. In the transient structure, unit and feature names are symbols. The values of features can be either symbols, logical variables (symbols that start with a question mark) or feature-value pairs. An example of a transient structure is shown here below.The hierarchy is drawn based on the subunits feature. In the value of that feature, the-38 and mouse-24 are symbols, not pointers to the units.

This transient structure consists of four units: root, mouse-24, the-38 and noun-phrase-56. We skip over the root unit for the moment, and come back to it in the next section. The body of the three other units consists of a set of feature-value pairs, in which the internal ordering is not important. The feature-value pairs have different kinds of values. The args feature for example takes a sequence of symbols as value (indicated by square brackets). The sequence consists here of a single element, ?x-756, which is a variable (as indicated by the question mark). The syn-cat feature takes a feature-value pair as value. The lex-cat feature takes an atomic symbol as value. Finally, the form and meaning features take a set of predicates as value, as indicated by the curly brackets (set) and the predicate notation of their elements (predicate).
The figure visualises the transient structure in a hierarchical way, namely as a tree. The visualisation is in this case based on the subunits feature, which has here a set of two symbols as its value. These symbols, the-38 and mouse-24 are equal to the unit names of two other units in the transient structure. This information is used to visualise the hierarchy. It is important to know that the transient structure is implemented as a set of units and that units are never nested. The value of the subunits features are just symbols that correspond to the unit name of other units and should not be thought of at pointers to these units. This means that multiple features can be used to represent different perspectives at the same time, for example constituent structure, dependency structure of information structure. The visualisation can simply be adapted by using a different feature for drawing the hierarchy or any other kind of network of units.
The Initial Transient Structure
The initial transient structure is the transient structure that is at the root of the search space. It contains all information that is known before the problem solving process has started. The initial transient structure is the result of a de-rendering process. This process transforms an input into a transient structure that can be used for problem solving. Although different de-render methods are implemented for different tasks, de-rendering for language processing is usually done in a standardised way.
In comprehension, the input consists of a string, such as “the smart mouse”. The input string is first tokenized. Then, a unique identifier symbol is attributed to each token, and a predicate string(identifier,token) is created. The unique identifier makes it possible to refer unambiguously to a specific token in the input, even if has the same form as other tokens in the input. This is for example the case when a word occurs more than once in the input utterance. Then, the internal ordering of the tokens is encoded in predicates as well. This is done using three kinds of predicates: meets(identifier-1,identifier-2) indicating binary left-right adjacency, precedes(identifier-1,identifier-2) indicating a binary precedence relation, and sequence(identifier-1,identifier-2,…, identifier-n) capturing the complete sequence. Finally, a feature form, which gets as value the set of string, meets, precedes and sequence predicates, is added to a unit called root in the transient structure. An example of an initial transient structure for the utterance “the smart mouse” is shown here:

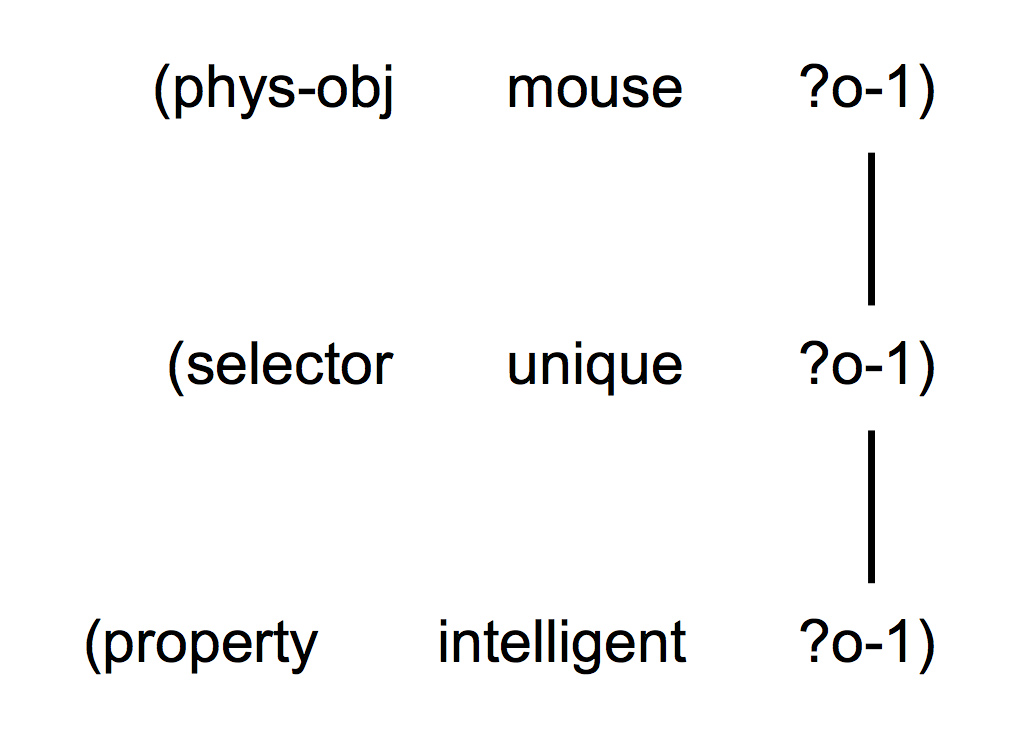
In formulation, the input consists of a meaning representation. As the meaning representation is typically already specified in the form of a set of predicates, no additional pre-processing steps are needed. A feature meaning, with as value the meaning predicates from the input is added to the root unit. The initial transient structure for the meaning representation {(selector unique o-1) (phys-obj mouse o-1) (property intelligent o-1)} looks as follows:

The initial transient structures contain thus a single unit, named root, with either a form feature (in comprehension) or a meaning feature (in formulation). The value of this feature is a set of predicates capturing the information in the input. These predicates will later be used by constructions during the problem solving process.
Constructions
Constructions are the operators in the problem solving process. Based on information present in a transient structure, they can build a new transient structure with more information added. The same constructions and processing mechanisms are used in comprehension and formulation, making FCG a truly bidirectional language processing framework.
Design and Structure
Like transient structures, constructions are implemented as feature structures. But whereas the feature structures representing transient structures are simply sets of units, those representing constructions are more structured. Constructions are data structures consisting of two parts:
-
Conditional Part: The conditional part specifies the preconditions of the construction. It consists of one or more units. The unit names are variables and the unit bodies are split into two parts: the comprehension lock and the formulation lock. The comprehension locks specify the preconditions of the construction in comprehension and the formulation locks specify the preconditions in formulation. A construction can apply in comprehension when the comprehension locks of the units on its conditional part match the transient structure and the construction can apply in formulation when the formulation locks match the transient structure. Matching is a unification process that succeeds if for each unit on the conditional part of a construction, a unit in the transient structure can be found such that the active locks (comprehension locks in comprehension, formulation locks in formulation) unify. The non-active locks are merged into the transient structure. Merging is an other unification process, in which on top of matching, features that are present in the construction but not in the transient structure are added. In the visualization of a constructions, the conditional part is written on the right-hand side of the arrow. For each conditional unit, the comprehension lock is written above the horizontal line and the formulation lock below.
-
Contributing Part: The contributing part of a construction is written on the left-hand side of the arrow. It contains zero or more units, of which the names are variables. When the conditional part of a unit matches a transient structure, the units on the contributing part are merged into the structure. When the contributing part contains features that cause conflicts during merging, the process fails and the construction cannot apply. If merging succeeds, the construction application succeeds.
A schematic representation of a construction in FCG, with its conditional part on the right and its contributing part on the left:
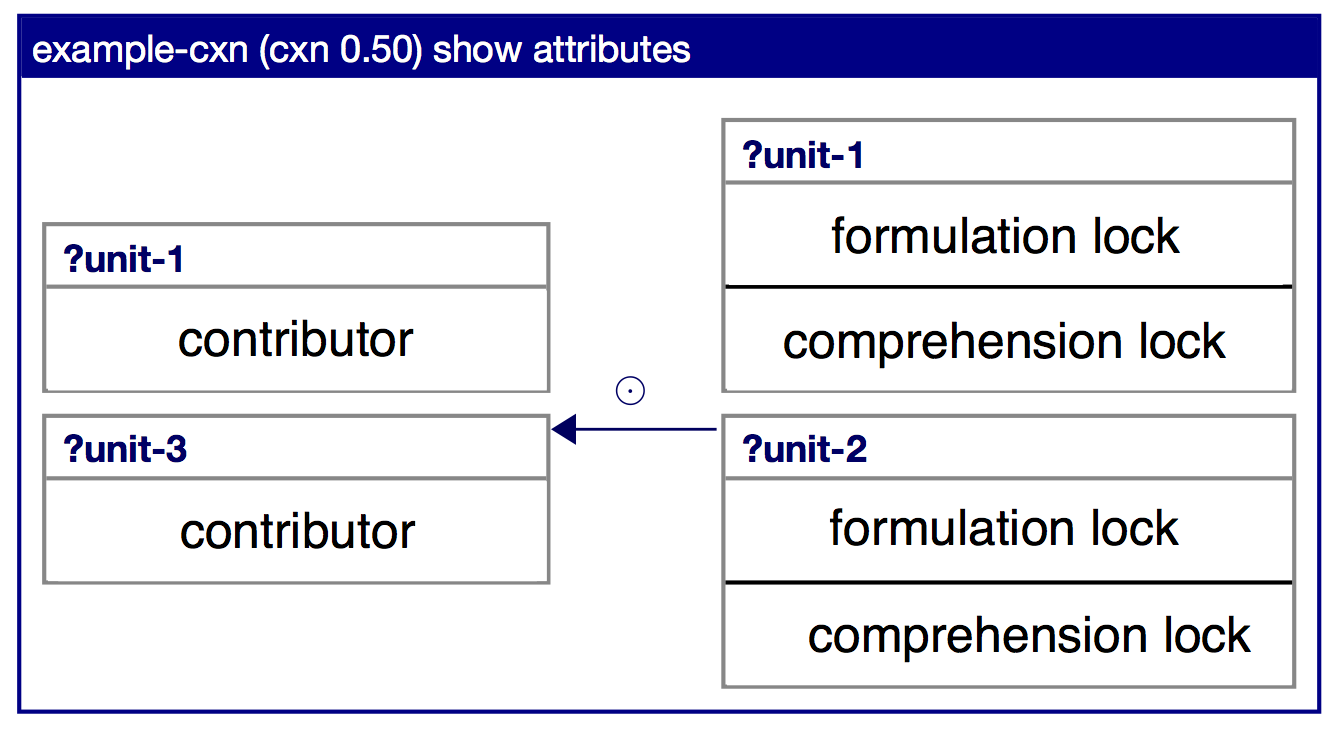
Two units with their comprehension and formulation locks are shown in the conditional part and two units with their contributor are shown in the contributing part. Note that the unit names are variables, and that the unit name of one of the units of the contributing part is bound to the unit name of one of the units of the conditional part.
There are no restrictions on what can be written on the left-hand side or right-hand side of a construction, which makes an FCG grammar unrestricted (type-0 grammar) in the Chomsky hierarchy.
Feature Types
We previously defined construction application as matching the active locks of the construction with the transient structure and merging the non-active locks and the contributors into the transient structure. I have not given a precise formalisation or algorithm for the matching and merging operations other than describing them as unification processes. In fact, FCG allows for a representation of features that is so expressive that features can trigger the use of a specific matching and merging algorithm. The algorithms are associated to features on grammar level or construction level by the declaration of feature types and are reflected in the visualisation of feature-value pairs. Note that feature types in FCG have nothing to do with “typed feature structures”, which are not used in FCG at all.
We briefly discuss the feature types that are commonly used in FCG, without going into too much detail.
-
Default Feature Type: If no other type is declared for a certain feature, the FCG engine will assume that it is of this default type. The feature has a value that is either atomic, i.e. a symbol or variable, or complex, in which case it consists of one or more feature-value pairs. In matching, the feature name should be present in the transient structure. If the value is atomic, it should unify with the value in the transient structure. If it is complex, the feature-value pairs in the construction should be a subset of the feature-value pairs in the transient structure, with each corresponding pair matching. In merging, the feature should not necessarily be present in the transient structure. If it is already there, the bindings from matching are instantiated. If it is not, the feature and its value are added to the transient structure. The value of a feature of the default type cannot have multiple features with the same feature name.
-
Set: This feature type indicates that the value of a feature is a set. The value is written between curly brackets. In matching, the FCG engine checks whether the elements in the value of the feature in the construction unify with a subset of the elements in the value of the same feature in the transient structure. In merging, the bindings from matching are instantiated and any new elements in the value are added to the transient structure. In sets, the same element can occur in the value multiple times.
-
Sequence: The value of a sequence feature is written between square brackets. In both matching and merging, the order and number of elements in the value is meaningful and every element should match and merge with the corresponding element in the transient structure.
-
Set-of-predicates: This feature type is very similar to the set feature type, but the elements of the value here are predicates. This feature type is most often used with the form and meaning features in FCG. The predicates are written in predicate notation and placed in curly brackets.
-
Sequence-of-predicates This feature type is very similar to the sequence feature type, but the elements of the value here are predicates. The predicates are written in predicate notation and placed in square brackets.
Another device that can be used in a construction to call a specialised matching and merging algorithm is the negation operator. This operator can be used to indicate that a certain feature-value pair or set element should NOT be present in the transient structure. Negation is indicated by adding the symbol in front of a feature or set element. Negations are only matched and not merged into the transient structure.
# Operator
One of the most widely used operators is the # operator (hash-operator). By putting a # sign in front of a feature in one of the locks of a construction, that feature is not matched in the corresponding unit in the transient structure, but in the root unit. In the merging phase, it is taken from the root unit and merged into the unit it is specified in. If this unit does not exist yet, a new unit is created. The # operator can be thought of in terms of cutting and pasting a feature from the root to an other unit. The # operator is extensively used by morphological and lexical constructions to match on strings and meaning predicates from the input. Grammatical constructions often use this operator to match on word-order predicates.
Let us have a look a construction that employs the # operator, namely the mouse-cxn:
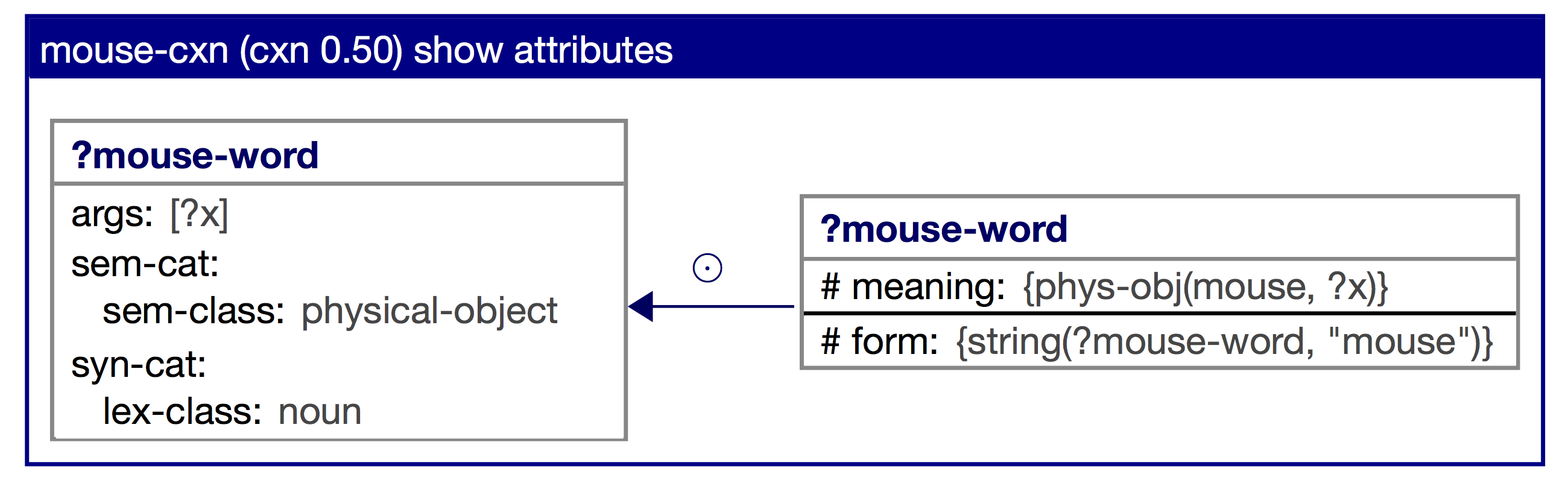
This construction has one unit on the conditional part, with a form feature in the comprehension lock and a meaning feature in the formulation lock. Both features are preceded by a #. We will now apply the construction to the initial transient structure shown above. In comprehension, the construction will match the form feature in the root unit of the transient structure. Matching will succeed and in merging, the construction will create a new unit, called mouse-word-xx. Then, it will move the string(mouse-27, “mouse”) predicate to the form feature of this new unit. It will also add the meaning feature from the formulation lock and all features from the contributor. In formulation, the construction will match the meaning feature in the root unit, move it to a new unit and add the form feature from the comprehension lock as well as all features from the contributor.
Footprints
When the active locks of a construction match with a transient structure and the non-active locks and contributors are not in conflict with the transient structure, a construction can apply. This creates the need for control mechanisms preventing that a construction keeps applying an infinite number of times, as the transient structure usually still satisfies the active locks of the construction after its application. One way of preventing the reapplication of a construction is to use the # operator in one of the locks. As the “hashed” feature is moved from the root into an other unit, it cannot be matched in the root anymore and the construction cannot apply a second time.
A second mechanism that has a long history in FCG consists in leaving a footprint in the transient structure and not applying a construction if its footprint is already there. Concretely, when a construction applies, it merges a feature footprints with as value a set containing the construction name into one of the units in the transient structure that also appears on the conditional part. In the lock of this unit on the conditional part, a negated feature (using the negation operator ) footprints with as value a set containing the construction name is added. The first time that the construction applies, the conditional part is satisfied and the footprint is merged in. The second time, the negated feature is in conflict with the footprint and the construction cannot apply. Footprints cannot only be used to prevent the same construction from applying, but can also reduce the search space by blocking large numbers of mutually exclusive constructions.
The most recent FCG notation handles footprints behind the scenes. To each lock that contains no # operator of each unit on the conditional part of a construction, a negated footprints feature is added. To the contributor of the corresponding unit, the footprints feature itself is added. This system ensures that by default, a construction can only apply once using the same units to satisfy its locks. If the grammar designer needs more fine-grained control over the footprints, he can simply turn off the automatic footprints for a single construction or an entire grammar. In that case, he becomes once again responsible for managing footprints himself.
The Construction Inventory
In FCG, a grammar is concretely implemented as a construction inventory. The construction inventory contains not only the constructions of a grammar, but also all information that is required to use the grammar in processing. This information consists of the declaration of feature types, a configuration object for processing and a configuration object for visualisation. The feature types declaration holds the feature types that are used throughout the grammar, although they can be overloaded on construction level. The configuration object for processing specifies many different processing options, including the required render and de-render method, search algorithm, maximum search depth and goal tests. The configuration object for visualisation specifies a.o. which features should be used to draw hierarchies and which level of detail should be shown in the visualisation, e.g. for debugging purposes.
Depending on whether a grammar supports meta-layer processing or type hierarchies, the construction inventory also holds a list of diagnostics and repairs or the type-hierarchy that needs to be build up or used.
Construction Application and Search
Now that we have seen what transient structures and constructions look like, we will have a closer look at how the FCG engine deals with the construction application and search processes. As explained above, the aim of the FCG engine is to find a pathway, i.e. a sequence of construction applications that leads from the initial transient structure to a transient structure that qualifies as a goal state.
In essence, the construction application process is steered by two mechanisms: the queue regulator and the construction supplier. The task of the queue regulator is to select the transient structure to which a new construction will be applied. It determines which partial pathway will be explored further. The task of the construction supplier is to select a construction that will be matched with a certain transient structure. Together, these two mechanisms regulate which part of the search space will be explored.
In its most basic setting, the queue regulator always selects the transient structure that was most recently added to the queue, leading to a depth-first exploration of the search space. The construction supplier in its most basic setting randomly picks a construction from the construction inventory. If the construction can apply, the resulting transient structure is added to the queue and the queue regulator selects this new transient structure. If no construction can apply, the queue regulator will backtrack to the previous node in which not all constructions from the transient structure were tried. Obviously, exploring the search tree in an uninformed way is not feasible for large search spaces. For this reason, FCG provides a number of mechanisms for steering the search process in a way that a solution can be found by exploring only a very small part of the search space.
Construction Sets and Construction Networks
A first way to make the task of the construction supplier easier, is to internally structure the constructions in the construction inventory. There are two common ways for doing this, using construction sets or construction networks.
When using construction sets, the constructions of a construction inventory are divided into two or more sets. The sets are ordered, with potentially a different ordering for comprehension and formulation. At first, the construction supplier will only supply constructions from the first set. When all these constructions have been supplied, it will continue with constructions from the second set and further sets, until all sets have been exhausted. Construction sets can drastically reduce the search space, as they ensure that certain constructions can only be applied after other constructions have been tried. It is for example common to specify that the set of morphological constructions should be applied first in comprehension and last in formulation. This makes sure that at least all morphological information is known before starting to apply grammatical constructions in comprehension, and that all grammatical information is known before starting to realise words as specific morphologic forms in formulation.
Construction networks, also called priming networks, organise the constructions in the construction inventory as a network. Each construction has ingoing and outgoing priming links connecting the construction with other constructions. The construction supplier will first supply the constructions that are primed by outgoing links. The links can be trained using a test corpus or in a multi-agent experiment. The construction networks capture which constructions often apply after a given construction in a successful pathway. By doing this, they manage to extend a partial pathway immediately with a construction that is likely to lead to a solution and therefore reduce the search space.
Hashing Constructions
For any realistic grammar of an existing language, the construction inventory easily consists of over 50.000 constructions. Most of these however, are morphological or lexical constructions. The preconditions of these constructions are very straightforward. In comprehension, they only require a string present in the input and in formulation, they only need a meaning predicate present in the input. Instead of looping through all morphological and lexical constructions and matching them with the transient structure, we organise these constructions in two hash tables. The first hash table has strings as keys and a list of constructions that match on these strings as values. The second hash table has meaning predicates as keys and a list of constructions that match on these meaning predicates as values. The construction supplier can now find a small set of constructions to match for every string or meaning predicate in constant time. When all strings or meaning predicates are moved out of the root unit, the high number of lexical and morphological constructions should not be considered anymore by the construction supplier. Using hashed construction sets, a grammar can be extended with as many lexical and morphological constructions as necessary, without causing any performance loss.
Scoring Constructions and Transient Structures
Scores can be assigned to both constructions and transient structures. Scores of constructions can be used by the construction supplier while scores of transient structure can be used by the queue regulator.
In evolutionary experiments, the score of a construction reflects how likely this construction is to lead to successful communication. When used in a successful communicative interaction, its score will increase, while when used in an failed interaction, its score will decrease. The construction supplier will select first constructions with a higher score. These scores are thus mainly used to lead the search process to a specific solution state, rather than to lead it faster to any solution state.
The score of a transient structure estimates how far away this state is from a solution state. Heuristic search algorithms (such as A*) rely on this score for deciding which partial pathway in the search tree should be pursued. There has been little research into finding good estimates for the scores of transient structures. The most commonly used heuristic is the number of constructions that have applied so far, assuming thus that the deepest path is most likely to lead to a solution. It would however be interesting to study the influence of other factors, such as the number of variable links in the meaning representation.
Grammar Design
Last but not least, the design of the constructions in the grammar itself has also a major influence on the size of the search space. As a general rule, it should be avoided that two constructions with conflicting features can apply to the same transient structure. If certain information is not yet known at one point in processing, it is preferable to underspecify the corresponding features as compared to splitting the search tree into two hypotheses. For example, a morphological construction realising an article as a singular form should only apply after a noun phrase has been build and the number of the noun with which the article needs to agree with is known.
Goal Tests and Solutions
Every node in the search tree contains a transient structure. At the moment that the node is created, all goal tests specified in the construction inventory are run on the node. If all goal tests succeed, the node is returned as a solution. If one or more goal tests fail, the search process continues (see Figure below). In comprehension, goal tests typically fail when other constructions can still apply, when the root unit still contains strings or when the meaning predicates in the transient structure are not linked into a single semantic network. In formulation, goal tests typically fail when other constructions can still apply or when the root unit still contains meaning predicates.
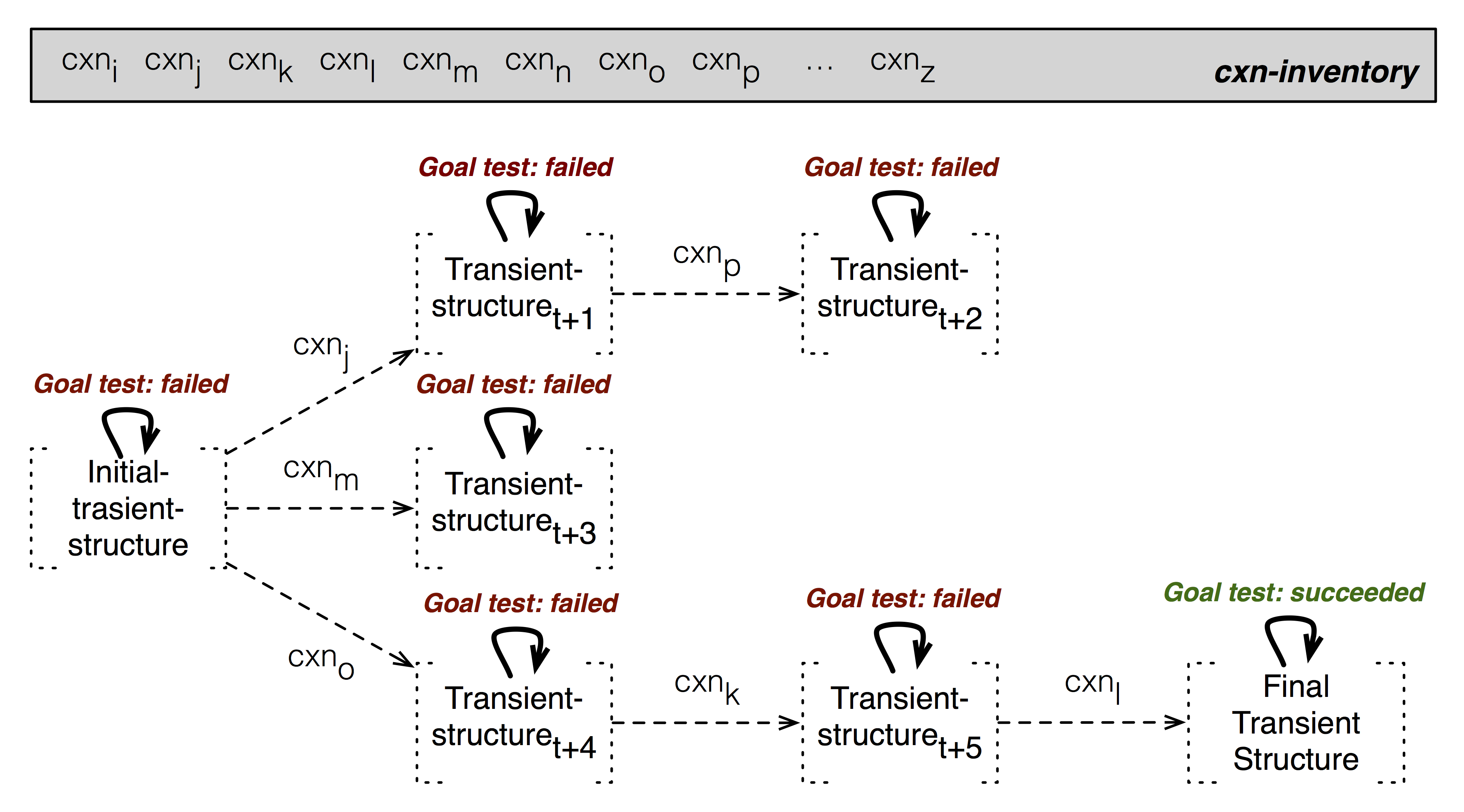
When all goal tests succeed and a node is returned as a solution, the final transient structure is rendered. In comprehension, rendering is done by extracting all predicates from the meaning feature in every unit of the transient structure. These meaning predicates are then drawn as a semantic network, such as:
In formulation, rendering is done by extracting all predicates from the form feature in every unit of the transient structure. Then, the strings in the string(identifier,string) predicates are concatenated taking into account the ordering constraints in the other predicates. The output in comprehension is a semantic network and the output in formulation is an utterance.
Meaning Representations
FCG does not impose a particular kind of meaning representation and leaves its design up to the grammar designer. As long as the semantic networks are built up from predicates that share arguments by linking variables, FCG can handle the meaning representation without any additions necessary. Two types of meaning representation are commonly used with FCG. If the aim is to ground the meaning in the sensory-motor systems of physical robots, a procedural semantics called Incremental Recruitment Language (IRL) is used. If this is not the aim, a minimal form of predicate calculus is used.
The examples used here are characterised by a minimal form of predicate calculus. All predicates are typed and their arguments can only be constants and variables. The predicates are written in the following form: type(predicate, arg_1, arg_2, ..., arg_n). By linking the arguments of different predicates, complex compositional meanings can be expressed.
Meta-Layer Problem Solving and Learning
So far we have looked at how FCG implements language processing as a problem solving process. During this process, constructions are consecutively applied to the initial transient structure until a solution is found. This assumes that all linguistic knowledge that is necessary for processing the input utterances or meaning representations is captured by the constructions of a grammar. There are two problems here. The first problem is that it remains implicit where and how the constructions of a grammar originated. The second problem is that language is constantly evolving and full of innovations, making it an absolute necessity for a grammar to be dynamic, flexible and open-ended. The two problems are closely related and boil down to the question of how a computational construction grammar system can deal with input that is not (yet) covered by a grammar, and how new lexical and grammatical constructions can be learned. In FCG, this is achieved by a meta-layer architecture, as discussed in the next sections.
Meta-Layer Architecture
FCG’s meta-layer architecture divides language processing into two layers: the routine layer and the meta-layer. The routine layer employs the described machinery for construction-based language processing and is optimized for efficient processing of input that is covered by the grammar. The meta-layer is designed to process input that is not covered by the grammar and to learn new constructions from previously unseen observations. The meta-layer architecture consists of three components: diagnostics, repairs and consolidation strategies.
-
Diagnostics. Diagnostics are tests that are run after each construction application and inspect the resulting transient structure for any abnormalities or potential problems. If a diagnostic detects an abnormality, it creates a problem of a certain type, e.g. a problem of type
unknown-stringorunconnected-semantic-network. The problem object can also hold further information that is added by the diagnostic, such as the string that was not covered or the construction that has just been applied. Diagnostics have access to the complete construction application process, including the search tree, the previously applied constructions, the transient structures that these constructions have created and the construction inventory. Diagnostics are specified on grammar level and stored in the construction inventory. The problems detected by the diagnostics are local to one branch in the search tree. -
Repairs. Repairs are methods implementing problem solving strategies. They specialise on one or more classes of problems that are triggered by diagnostics. When faced with a problem, a repair will try to find a solution in the form of a fix object. The type of the fix and the way in which the fix repairs the problem are open-ended. The most common type of fix in FCG is the fix-cxn, in which the fix comes in the form of a construction. The application of the fix-cxn to the transient structure then repairs the problem. The repair methods are run after each construction application, just after the diagnostics are run. They can repair problems that were triggered in the same node of the search tree, but also problems from earlier nodes that were not yet fixed. Just like in the case of diagnostics, repairs have access the to the complete construction application process, the search tree and the construction inventory. Repairs are specified on grammar-level and stored in the construction inventory.
-
Consolidation Strategies. While diagnostics and repairs diagnose and solve problems at the meta-layer, consolidation strategies are designed to store solutions to these problems for later reuse during routine processing. In the case of the fix-cxns discussed above, the transfer from the meta-layer to the routine layer is rather straightforward. As the fix-cxns work in exactly the same way as regular constructions, they can, in principle, simply be added to the construction inventory. However, only fixes that successfully repaired a problem should be consolidated. This is done by only storing fixes of branches in the search tree that ultimately led to a solution node. It is not easy to strike the optimal generality-specificity balance for a fix. Fixes that are too specific will only apply to exactly the same observation in the future, whereas fixes that are too general might apply to transient structures they should not apply to. This dissertation makes a major contribution to this generality-specificity balance by incorporating anti-unification and pro-unification algorithms in FCG.
A schematic representation of the meta-layer architecture in FCG is shown here:
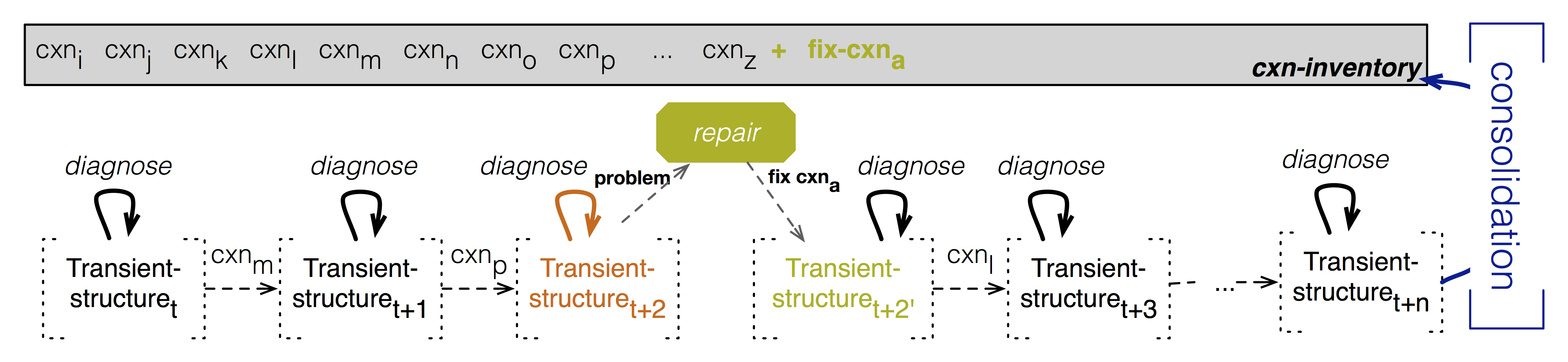
Diagnostics are run after every construction application. The transient structure in which a problem is diagnosed is shown in orange. The transient structure that is the result of applying the fix-cxn is shown in green. At the end of the branch of the search tree, the fix-cxn is added to the construction inventory for later reuse in routine processing.
Library of Diagnostics and Repairs
The power of a meta-layer architecture lies in the diagnostics, repairs and consolidation strategies that are used. Although different tasks and grammars often require highly specific diagnostics and repairs, certain problems occur in almost any task and grammar. In order to solve these reoccurring problems in a user-friendly and standardised way, we have included a library of basic diagnostics and repairs in the FCG system. The following situations are covered:
-
In comprehension, the input contains a form that is not covered by any construction. A new lexical construction needs to be created, mapping the perceived form to a hypothesized meaning predicate.
-
In formulation, the input contains a meaning predicate that is not covered by any construction. A new lexical construction needs to be created, mapping the predicate to a new form.
-
In comprehension or formulation, no solution can be found. This can be due to a case of coercion, an agreement mismatch, a word order error or a similar problem. Conflicting features of an existing construction need to be relaxed, in order for the construction to apply.
-
In comprehension or formulation, variables in two meaning predicates need to be bound to each other. A new phrasal construction needs to be created, capturing the variable equalities and the word order or markers.
FCG Interactive: Web Service and API
In order to facilitate the dissemination of FCG, and in particular of the research project presented in this dissertation, I have created an interactive web service and API for the FCG framework. While the interactive web service provides interested people with the opportunity of getting to know FCG without needing to install the software environment on their computers, the API makes it easy for developers to integrate FCG as a language processing component into any application.
FCG Interactive Web Service
The FCG Interactive web service was launched on the 17th of October 2016 at the Intensive Science Scientific Festival, an event organised by Sony Computer Science Laboratory Paris for celebrating its 20th anniversary. Since then, it is publicly available at https://www.fcg-net.org/fcg-interactive. The web service has Fluid Construction Grammar running under the hood, with grammars for different languages loaded in memory. The user can select a grammar and enter the utterance or meaning representation that he wants to process. Depending on the input, he can then click comprehend to comprehend the input utterance, comprehend-and-formulate to comprehend the input utterance and reformulate the comprehended meaning, formulate for formulating the input meaning representation, or formulate-and-comprehend for formulating the input meaning representation and recomprehending the produced utterance. The user can also choose between two visualisation options, the first one including the complete construction application process, and the second one including the final result only and hence speeding up the whole process with a few seconds.
The visualisations shown by the interactive web service are generated using FCG’s default, browser-based visualisation library, which makes ample use of expandable/collapsible elements. These elements allow to present a very clear, high-level overview of the construction application process and its result, while full detail on intermediate results, including transient structures, applied constructions and bindings, are only a single click away.
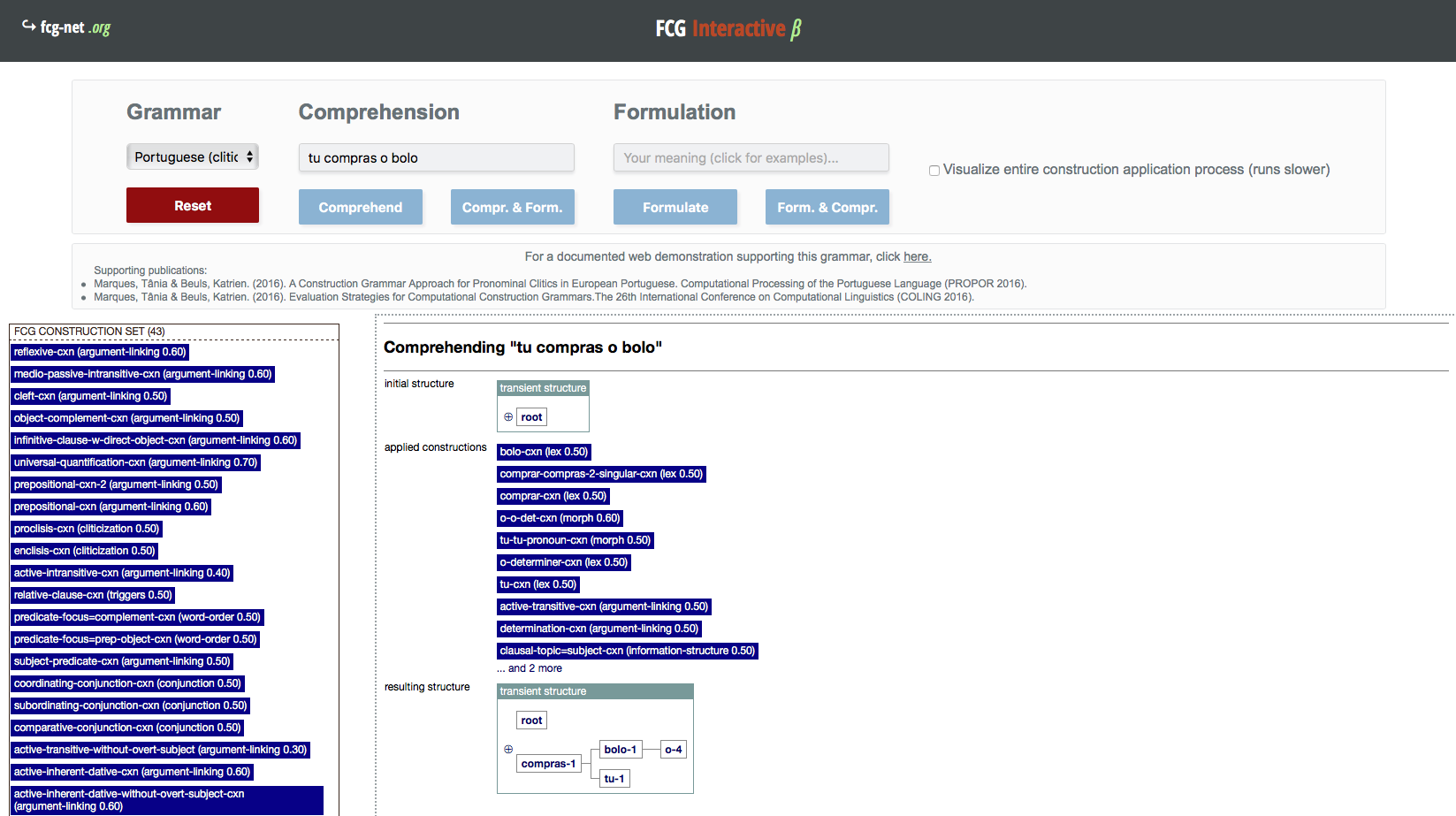
The upper part in this screenshot shows the fields that take input from the user: grammar name, utterance to comprehend or meaning representation to formulate, and requested visualisation. The lower part displays the construction inventory of the chosen grammar on the left, and the analysis of the processed utterance/meaning representation on the right. The screenshot shows the comprehension process for the utterance “tu compras o bolo” (you buy the cake), using a grammar that focuses on clitics in Portuguese.